
IBM Advances AI Model Training with Proprietary Vela Cluster and Storage Scale Integration
IBM has made significant strides in AI model training with the development of its proprietary Vela cluster, which is intricately designed using Storage Scale.
This advanced infrastructure is at the core of IBM's AI endeavors, providing the computational backbone for training the next generation of AI models. Notably, IBM's latest AI studio, watsonx.ai, which became widely available in July 2023, was trained on this very Vela cluster.
The Vela infrastructure is a testament to IBM’s commitment to pushing the boundaries of AI technology. Storage Scale, a sophisticated parallel file system, is integral to Vela’s design. It functions as a quasi-cache in front of object storage, dramatically enhancing data input/output (I/O) speeds.
This setup ensures that GPUs are consistently engaged, eliminating potential bottlenecks and boosting overall processing efficiency.
Active File Management (AFM) technology is configured to connect filesets transparently to object storage buckets, representing objects in buckets as files within the file system and pulling data from object storage on demand. When files are written to the file system, AFM eventually migrates them to object storage.
The total capacity of this Scale parallel file system, encompassing all attached devices, reaches into the hundreds of terabytes. The research paper explains that Scale is deployed in Vela using a disaggregated storage model, with the dedicated Scale storage cluster comprising tens of IBM Cloud Virtual Server Instances (VSIs), each equipped with two 1TB virtual block volumes. These virtual block volumes, hosted on a next-gen cloud-native and high-performance block storage service in IBM Cloud, meet the high throughput demands of model training workloads.
Performance Improvement with Scale-based Storage
Read Bandwidth:
- Nearly 40x speedup compared to NFS.
- 1 GBps with NFS vs. 40 GBps with Scale.
Write Bandwidth:
- Nearly 3x the write bandwidth of IBM COS.
- 5 GBps with IBM COS vs. 15 GBps with Scale.
Impact on AI Training Jobs:
- Granite-13B used NFS.
- Granite-8B used Scale.
Performance Metrics Based On:
- Iteration times for AI training jobs.
Training jobs on Vela can take a month or more to complete, as highlighted in the research paper.
The innovation behind Vela’s architecture has been meticulously documented in a research paper that is freely accessible, offering insights into the technology that powers IBM's generative AI model development.
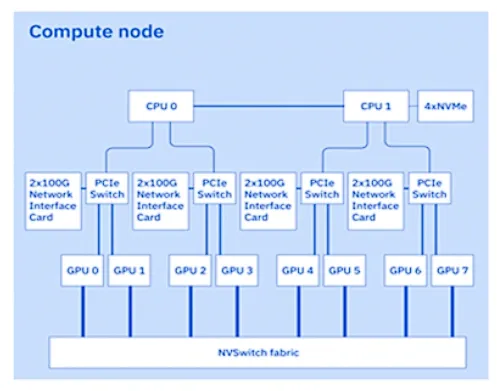
Vela is characterized as a sophisticated cluster of CPU/GPU servers that host virtual machines within the IBM Cloud. Initially, the server nodes were equipped with twin-socket systems featuring Cascade Lake Gen 2 Xeon Scalable processors, complemented by 1.5TB of DRAM and 4 x 3.2TB NVMe SSDs.
These nodes also housed 8 x 80GB Nvidia A100 GPUs, utilizing NVLink and NVSwitch for seamless connectivity. In a subsequent upgrade, the Xeon processors were replaced with the more advanced IceLake processors, further enhancing Vela's computational capabilities.
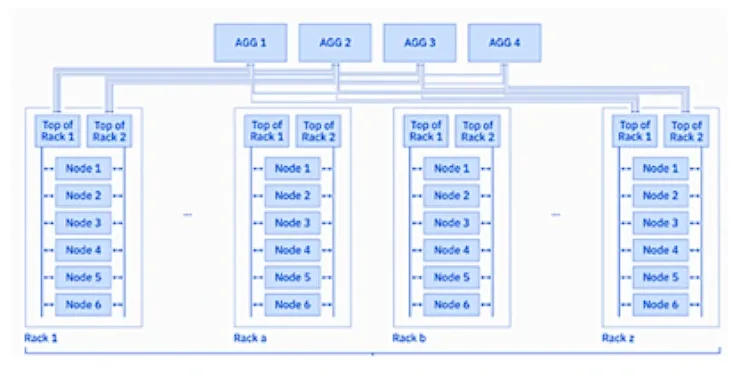
The Vela cluster is interconnected through a 2-level spine-leaf Clos structure, a nonblocking, multistage switching network built on 100Gbps network interfaces. This architecture ensures seamless communication between the nodes.
The storage drives are accessed via Remote Direct Memory Access (RDMA) over Converged Ethernet (RoCE) and GPU-direct RDMA (GDR).
This advanced setup, combining GDR with RoCE, enables GPUs in one system to directly access the memory of GPUs in another system through Ethernet network cards, significantly enhancing data transfer speeds and efficiency.
The networking subsystem is also equipped with built-in congestion management to maintain optimal performance.
IBM operates Vela through its Cloud as an Infrastructure as a Service (IaaS), with Red Hat OpenShift clusters managing tasks across the entire AI lifecycle, from data preparation to model training, adaptation, and deployment.
The AI training data is stored in object storage, which proved too slow for both reading (job loading) and writing (job checkpointing). To overcome this, IBM implemented Storage Scale as a high-performance file system between the object storage and GPUs, serving as an intermediating cache.
This allows data to be loaded into GPUs much faster, accelerating the start (or restart) of training jobs, and enables model weights to be checkpointed to the file system at significantly higher speeds compared to writing directly to object storage.
The unique technology within Storage Scale also facilitates the asynchronous transfer of checkpointed data to object storage, without impeding the progress of training jobs.
Within Vela, a Scale client cluster runs across GPU nodes in container-native mode using the CNSA edition of Scale. The infrastructure leverages Kubernetes operators to deploy and manage Scale in a cloud-native manner and utilizes a CSI Plugin for provisioning and attaching persistent volumes based on Scale.
The client cluster, lacking locally attached storage, remotely mounts the file system in the storage cluster. This design allows for independent scaling of compute and storage clusters based on changing workload demands.

In 2023, Vela underwent a major upgrade with the introduction of the more robust Blue Vela cluster, which went live in April. This new iteration was developed in collaboration with Dell and Nvidia. We’ll delve into the details of this enhanced infrastructure in a forthcoming article.















