
Large Language Models (LLMs) like GPT-4 are reshaping what's possible with AI—from revolutionizing natural language processing to driving advancements in content creation and conversational tools.
Turning this AI power into production-ready applications isn't always easy. LLMs come with demanding requirements—high compute power, scalability, and intelligent traffic handling.
Without the right infrastructure, even the most advanced models can struggle to perform in real-world environments.
This is where Kubernetes steps in. As the go-to container orchestration platform, Kubernetes offers a cloud-native foundation that’s both dynamic and reliable—perfect for managing LLM deployments.
This step-by-step guide dives into how you can deploy and scale an LLM-based app using Kubernetes.
Because at the end of the day, the real win isn’t just having a powerful model—it’s about making it work for your users, at scale, in the real world.
Before You Start: What You’ll Need
Step 1: Creating an LLM-Powered Application

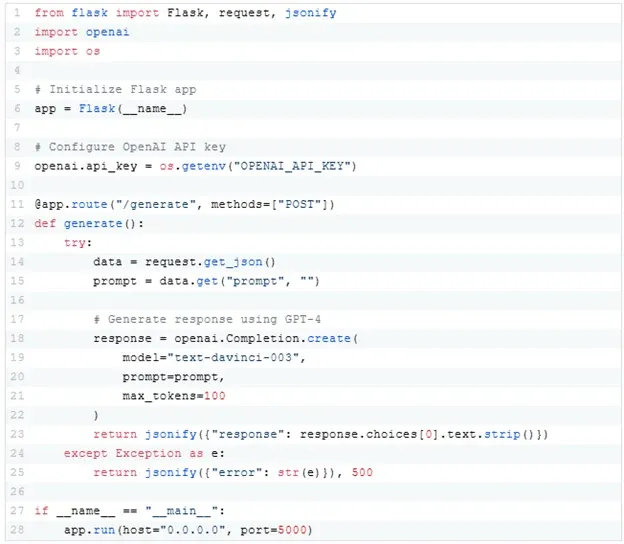
Step 2: Containerizing the Application
To deploy the application to Kubernetes, we need to package it in a Docker container.
Dockerfile
Create a Dockerfile in the same directory as app.py:
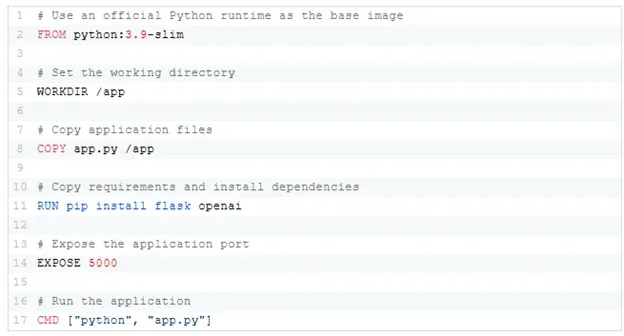
Step 3: Building and Pushing the Docker Image
Build the Docker image and push it to a container registry (such as Docker Hub).

Step 4: Deploying the Application to Kubernetes
We’ll create a Kubernetes deployment and service to manage and expose the LLM application.
Deployment YAML
Create a file named deployment.yaml:

Secret for API Key
Create a Kubernetes secret to securely store the OpenAI API key:
1 kubectl create secret generic openai-secret --from-literal=api-key="your_openai_api_key"
Step 5: Applying the Deployment and Service
Deploy the application to the Kubernetes cluster:
Once the service is running, note the external IP address (if using a cloud provider) or the NodePort (if using minikube).
Step 6: Configuring Autoscaling
Kubernetes Horizontal Pod Autoscaler (HPA) allows you to scale pods based on CPU or memory utilization.
Apply HPA
1 kubectl autoscale deployment llm-app --cpu-percent=50 --min=3 --max=10
Check the status of the HPA:
1 kubectl get hpa
The autoscaler will adjust the number of pods in the llm-app deployment based on the load.
Step 7: Monitoring and Logging
Monitoring and logging are critical for maintaining and troubleshooting LLM applications.
Enable Monitoring
Use tools like Prometheus and Grafana to monitor Kubernetes clusters. For basic monitoring, Kubernetes Metrics Server can provide resource usage data.
Install Metrics Server:
1 kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
View Logs
Inspect logs from the running pods:
1 kubectl logs <pod-name>
Step 8: Testing the Application
Test the LLM API using a tool like curl or Postman:
1 curl -X POST http://<external-ip>/generate \
2 -H "Content-Type: application/json" \
3 -d '{"prompt": "Explain Kubernetes in simple terms."}'
Expected output:
1 {
2 "response": "Kubernetes is an open-source platform that manages containers..."
3 }
Step 9: Scaling Beyond Kubernetes
To handle more advanced workloads or deploy across multiple regions:
-
Use service mesh: Tools like Istio can manage traffic between microservices.
-
Implement multicluster deployments: Tools like KubeFed or cloud provider solutions (like Google Anthos) enable multicluster management.
-
Integrate CI/CD: Automate deployments using pipelines with Jenkins, GitHub Actions or GitLab CI.
Building and deploying a scalable LLM application using Kubernetes might seem complex, but as we’ve seen, the process is both achievable and rewarding.
Starting from creating an LLM-powered API to deploying and scaling it within a Kubernetes cluster, you now have a blueprint for making your applications robust, scalable and ready for production environments.
With Kubernetes’ features including autoscaling, monitoring and service discovery, your setup is built to handle real-world demands effectively.
From here, you can push boundaries even further by exploring advanced enhancements such as canary deployments, A/B testing or integrating serverless components using Kubernetes native tools like Knative.
Want to learn more about LLMs? Discover how to leverage LangChain and optimize large language models effectively in Andela’s guide, “Using Langchain to Benchmark LLM Application Performance.”















