
Retrieval-Augmented Generation (RAG) has become a foundational architecture—supercharging large language models (LLMs) with external knowledge.
But what if retrieval wasn’t static?
What if AI could decide how and where to search, combining logic, memory, tools, and context to produce intelligent, real-world answers?
Welcome to the next frontier: Agentic RAG.
What Is Agentic RAG?
Agentic RAG = Agentic AI + RAG
It’s a new paradigm where an autonomous AI agent orchestrates the entire information retrieval and generation process—not just passively fetching documents from a vector store, but dynamically choosing strategies, tools, and sources depending on the query at hand.
In essence, Agentic RAG introduces reasoning, planning, and memory to the traditional RAG stack, turning what was once a linear retrieval process into a multi-layered decision engine.
How It Works: A Step-by-Step Breakdown
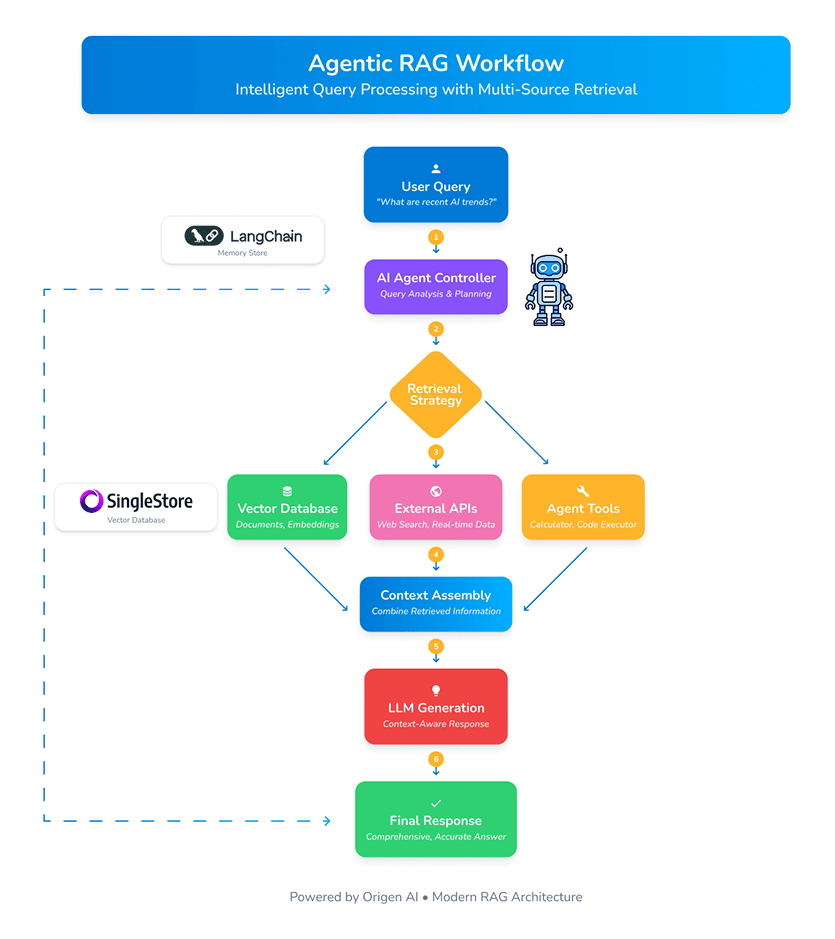
Agentic RAG introduces an intelligent, multi-layered process that goes far beyond traditional retrieval methods. Here’s how it works step by step:
1. AI Agent Controller
The journey starts with a user query—but instead of jumping straight to retrieval, the Agentic Controller first analyzes the request with purpose.
It identifies:
-
What type of information is needed
-
Where that information might live (e.g., internal vectors, APIs, memory)
-
Which tools or resources are required to generate an accurate response
This strategic planning phase allows the system to think before it searches—setting the foundation for intelligent decision-making.
2. Dynamic Retrieval
Unlike static RAG systems limited to vector stores, Agentic RAG dynamically chooses the most effective retrieval path:
-
Internal vector databases for pre-stored knowledge
-
External APIs or real-time search for up-to-date information
-
Specialized tools like calculators, code runners, or even other agents
This approach ensures the system selects the most relevant and efficient method—or combination of methods—based on the nature of the query.
3. Context Assembly: Synthesizing, Not Just Collecting
Once the data is gathered, the agent doesn’t simply dump it into the LLM. Instead, it enters the Context Assembly phase—where insights from multiple sources are merged and refined into a coherent, context-rich narrative.
It’s not about aggregation; it’s about smart synthesis across structured, semi-structured, and unstructured formats.
4. Contextual Generation with LLMs
With the finalized context in hand, the agent hands off the data to a large language model like GPT-4 or Claude.
The result? A nuanced, accurate, and fully contextual response—tailored specifically to the user's intent and grounded in real, validated knowledge.
5. Memory Loop: Learning from Every Interaction
One of the key differentiators of Agentic RAG is its persistent memory.
Every query, action, and result is:
-
Logged into the Memory Store
-
Used to refine future interactions
-
Adapted to maintain context across conversations
This enables the agent to improve continuously—learning from experience, adjusting strategies, and maintaining relevance over time.















