
In the era of big data, organizations generate vast amounts of information every second. Managing, storing, and analyzing this data efficiently is crucial for driving business intelligence, innovation, and informed decision-making.
Two of the most widely used data storage solutions are Data Warehouses and Data Lakes. While both serve as repositories for large-scale data storage, they are fundamentally different in architecture, purpose, and use cases.
This article explores the key differences between Data Warehouses and Data Lakes, their technological impact, and how companies like Origen provide solutions to optimize data management.
Understanding Data Warehouses

A Data Warehouse is a structured, centralized repository designed to store and manage processed, structured data. It is optimized for analytical processing, enabling businesses to gain insights through reporting and complex queries.
Key Characteristics of a Data Warehouse:
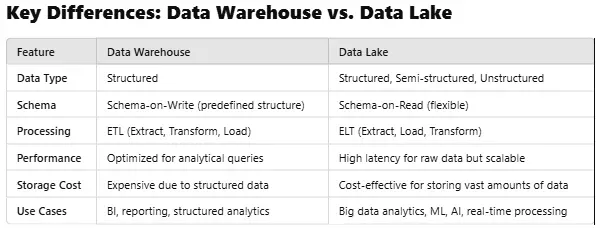
1. Structured Data: Information is stored in a predefined schema, meaning data must be cleaned and transformed before being loaded into the warehouse (ETL process).
2. Optimized for Analytics: Designed for business intelligence (BI) and analytics, making it easier to generate reports, dashboards, and predictive models.
3. Historical Data Storage: Primarily used for storing historical business data to identify trends and patterns over time.
4. High Performance: Query performance is fast due to the organized structure, indexing, and optimization for structured queries.
Common Use Cases:
-
Business Intelligence & Reporting: Enterprises rely on Data Warehouses to generate reports, monitor performance, and make data-driven decisions.
-
Financial Analysis: Banks and financial institutions use Data Warehouses for risk analysis, fraud detection, and transaction monitoring.
-
Healthcare & Pharmaceuticals: Used for patient record analysis, clinical research, and regulatory compliance.
Popular Data Warehouse Technologies:
- Amazon Redshift
- Google BigQuery
- Snowflake
- Microsoft Azure Synapse Analytics
- IBM Db2 Warehouse
Understanding Data Lakes
A Data Lake is a highly flexible storage solution designed to handle vast amounts of structured, semi-structured, and unstructured data. Unlike Data Warehouses, Data Lakes do not require a predefined schema, allowing organizations to store raw data in its native format.
Key Characteristics of a Data Lake:
1. Schema-on-Read: Unlike Data Warehouses, which follow Schema-on-Write, Data Lakes allow users to define the schema when retrieving data, offering flexibility for diverse datasets.
2. Handles All Data Types: Supports structured data (databases), semi-structured data (JSON, XML), and unstructured data (videos, images, logs).
3. Scalable & Cost-Effective: Built on distributed storage architectures, making them ideal for storing massive amounts of data at a lower cost.
4. Supports Advanced Analytics: Frequently used for big data analytics, AI, and machine learning, where raw data is processed dynamically.
Common Use Cases:
-
Machine Learning & AI: Data Lakes are widely used for training ML models, as they allow access to diverse, unprocessed data.
-
IoT & Sensor Data Storage: Companies handling IoT devices store continuous streams of unstructured sensor data in Data Lakes.
-
Customer Behavior Analysis: Retailers and e-commerce businesses use Data Lakes to track customer interactions and predict trends.
-
Log & Event Data Storage: IT teams store logs for security monitoring, system performance tracking, and troubleshooting.
Popular Data Lake Technologies:
- Amazon S3 (Simple Storage Service)
- Azure Data Lake Storage (ADLS)
- Google Cloud Storage
- Apache Hadoop & HDFS
- Databricks Delta Lake
Both solutions serve different needs—Data Warehouses are ideal for structured, analytics-driven decision-making, while Data Lakes are best suited for unstructured, exploratory, and AI-driven applications.
How Origen Provides Innovative Data Solutions
At Origen, we understand that businesses require a balanced approach to data management—leveraging the efficiency of Data Warehouses and the flexibility of Data Lakes. Our solutions bridge the gap between structured analytics and unstructured big data processing, ensuring organizations gain the most value from their data.
Origen’s Data Management Solutions:
Hybrid Data Platforms: We integrate Data Warehouses and Data Lakes into a unified data architecture, enabling seamless data movement and interoperability.
-
Advanced ETL & ELT Pipelines: Our automated pipelines ensure clean, high-quality data reaches the warehouse while raw, unstructured data remains available in the lake for advanced analytics.
-
Cloud-Native Storage & Processing: With support for AWS, Azure, and Google Cloud, we provide scalable and cost-efficient storage solutions.
-
AI & ML-Driven Analytics: Origen’s platforms enable AI-powered insights, helping businesses uncover patterns and optimize decision-making.
-
Security & Compliance: Our solutions ensure secure access control, encryption, and compliance with GDPR, HIPAA, and SOC 2 standards.
Choosing between a Data Warehouse and a Data Lake depends on your business needs. If your organization requires structured data analysis and reporting, a Data Warehouse is the ideal choice. However, if you need to store and analyze vast amounts of diverse, unstructured data for AI and big data applications, a Data Lake is the better option.
Are you looking to optimize your data architecture? Contact Origen today and take your data strategy to the next level!















